1. Introduction
Iro is a development tool designed to simplify the creation of syntax highlighters across many platforms.
Click here to load Iro, which features an embedded sample for immediate demonstration of key features.
1.1. Syntax Highlighters
Syntax highlighters typically uses rules to split text into smaller and smaller subregions; assigning each subregion a style.

1.2. Required Knowledge
Both Iro and this document require a working knowledge of regular expressions.
For beginners, links to tutorials are provided here.
1.3. Syntax Highlighting for Beginners
-
Imagine a hypothetical document containing some text.
-
Now imagine the first line in that document.
-
You wish to colour in that line of text according to some rules.
-
But for now, forget about colours.
-
What you really need is to designate the text into regions.
-
Once you have non overlapping regions, then you can style the text CSS style based on region assignments.
-
In Iro, these regions are called styles.
-
Styles can be setup with default rendering colours for the purposes of debugging.
-
You require one style per district region of text.
-
For example, a comment would be a region / style, a keyword would be a different style a bit of quoted text would be a different style, a literal number might be a different style, and so on.
-
Now, how to start zoning?
-
Most simple way is to run through a list of regular expressions and the first one that matches wins and consumes some text. Once it wins, the regular expression assigns a one or my style ids to grouped regions within its own match.
-
Then run through the list of regular expressions again starting from the position of the end of the last match.
-
If nothing matches, go to next line and start again.
-
The "main" context is the initial list.
-
Basic regular expressions are :pattern objects.
Here is a simple highlighter definition.
name = sample file_extensions [] = sample; styles [] { .comments : style color = "light_green"; .tree : style color = "orange"; } contexts[] { main : context { : pattern { regex \= (\boak\b) styles [] = .tree; } : pattern { regex \= (//.*) styles [] = .comments; } } }
Here is some text highlighted corresponding to the above definition.

| Please see the algorithm section for more detailed information. |
1.4. Supported Exporters
A single Iro language definition can export to the following formats.
Format |
Grammar Definition Language |
Platform |
Adopters |
XML |
OSX Based Editor |
||
Coffeescript |
Github’s own code editor, desktop app that sits on JavaScript foundations |
N/A |
|
Python |
Python Syntax Highlighting Library |
N/A |
|
Ruby |
Ruby Syntax Highlighting Library |
N/A |
|
JavaScript |
Code editor for web |
N/A |
|
YAML |
Cross platform commercial text editor |
N/A |
1.5. Goals
-
To make creating and debugging syntax highlighters as simple as is possible.
-
To act as a lingua franca (commonly understood) format; exporting to many different popular formats without requiring deep knowledge of the target formats.
1.6. Terminology
| Term | Description |
|---|---|
Iro Highlighting Model |
The model represented by the .iro file format. |
Derived Grammar |
Language grammar files generated by Iro (such as .tmLangauge files) |
Context / Lexical State |
A lexical state is a context in which to interpret text at the current cursor position. Context and Lexical state are used interchangably in Iro. |
1.7. Visualizing Regular Expressions
If you find any regular expression in this document difficult to read then copy and paste the expression into the excellent DebugEx tool and it will produce an excellent visualization.
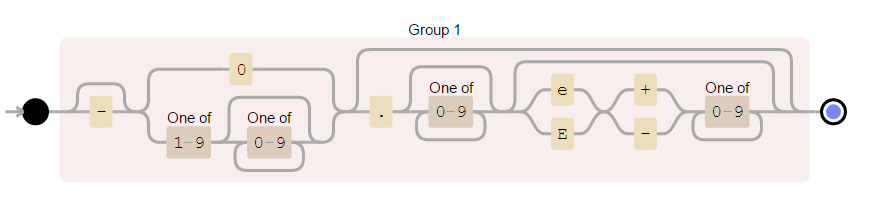
For example, in the JSON example, later in the document, I use the following regular expression without explanation:
((?:\-?(?:0|(?:[1-9][0-9]*)))(?:(?:\.[0-9]*)(?:(?:e|E)(?:\+|\-)[0-9]+)?)?)
1.8. Highlighting JSON With Iro
Let’s jump forward to a fully functional example, provided for those that prefer to copy paste and modify rather than read. Everything will be explained later in the document.
If your first reaction after (potentially) understanding the syntax is that this is an over simplification of JSON - then you are right, but you are also wrong. See : perfect is the enemy of good.
############################################################# ## JSON Syntax highlighter ############################################################# name = json file_extensions [] = json; contexts [] { main : context { : inline_push { regex \= (\{) styles [] = .punctuation; : pop { regex \= (\}) styles [] = .punctuation; } : include "main" ; } : inline_push { regex \= (\[) styles [] = .punctuation; : pop { regex \= (\]) styles [] = .punctuation; } : include "main" ; } : pattern { regex \= (,|\:) styles [] = .punctuation; } : inline_push { regex \= (\") styles [] = .punctuation; : pop { regex \= (\") styles [] = .punctuation; } : pattern { regex \= ((?:\\u[0-9a-f]{4})|(?:\\["\\/bfnrt])) styles [] = .escape_char; } : pattern { regex \= ([^\"\\]+) styles [] = .attribute_value; } } : pattern { regex \= ((?:\-?(?:0|(?:[1-9][0-9]*)))(?:(?:\.[0-9]*)(?:(?:e|E)(?:\+|\-)[0-9]+)?)?) styles [] = .special; } : pattern { regex \= (true|false|null) styles [] = .special; } : pattern { regex \= ([^\s]) styles [] = .illegal; } } } styles [] { .escape_char : style { textmate_scope = constant.character.escape pygments_scope = String.Escape color = #0a0 background_color = #232 } .illegal : style { textmate_scope = invalid.illegal pygments_scope = Generic.Error color = white background_color = red } .punctuation : style { textmate_scope = keyword.operator pygments_scope = Punctuation color = red_2 } .attribute_value : style { textmate_scope = string.unquoted pygments_scope = String.Char color = gold } .special : style { textmate_scope = storage.type pygments_scope = Keyword.Type color = #6bc } }
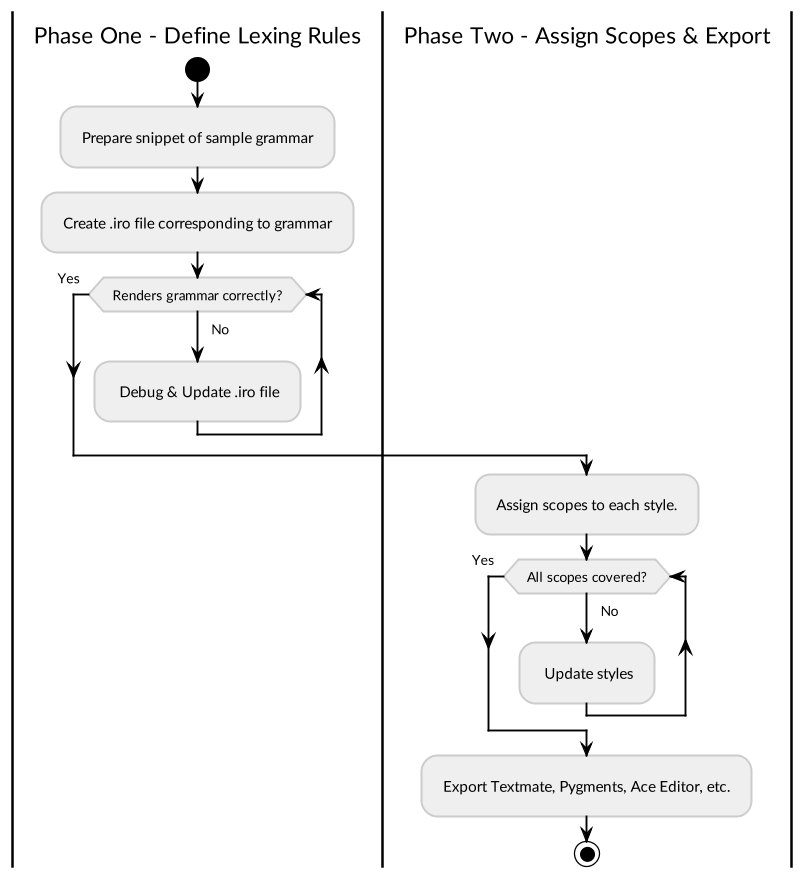
2. Typical Workflow
Use of Iro to create a new language definition (.iro file) is usually split into two distinct phases:
3. The Iro Highlighting Model (.iro file)
| Please notice that regular expressions use the \= operator. This is a feature of the Rion object notation language described here |
The .iro model is hosted in the Rion object notation language. The purpose of the Iro Highlighting Model is to act as a convenient editing and debugging format, to be used to create derived grammars for a variety of popular products.
The Iro Model is split up into 3 different sections:
-
Header
-
Styles
-
Contexts (also known as Lexical States)
3.1. Header Part
A language name and the file extensions are required at a minimum.
name = sample file_extensions [] = sample1, sample2;
Iro does not force uniqueness or names or file extensions, so do some research before naming your language.
At least one file extension is required. This may overlap with file extensions of other languages.
In this case we provide two file extensions 'sample1' and 'sample2'. The dot is not required as a prefix for file extension.
3.2. Styles
Styles should be set up per language concept, so that they can be colorized / stylised individually.
Styles serve two purposes.
-
Define a default stylesheet for a language for the purposes of debugging.
-
Provide a lookup table to exporter-specific scopes.
At minimum, only a color is required. By default, Iro uses a dark background color. This color ONLY applies to Iro debugger and has no relation to allocating textmate (or other exporter) scopes.
styles[] { .sl_comment : style { color = green } }
A fully loaded style contains mappings to fixed scope ids for each exporter. It is not required (but it is advised) to have full coverage of scopes for each exporter per style.
The scope coverage report will inform the grammar author of if they have correctly mapped internal Iro styles to all exporters scopes without ambiguity.
styles[] { .sl_comment : style { color = green textmate_scope = comment.line pygments_scope = Comment } }
| Ace scope can be supplied seperately to TextMate scope but it inherits the TextMate scope by default; so generally speaking Ace scope is fine not to configure directly. The Scope Summary report will let you know if you missed something. |
If no color is defined, then Iro will use the default background color and a shade of white for the text color (assuming using the default dark theme, black in the case of the secondary light theme).
If you define no colors or styles, it is counter intuitive as to the purpose of using a syntax highlighter at all so it is recommended to set up every style with some type of color or formatting.
Here is a set of attributes that apply to styles. All attributes are optional.
| Id | Description | Sample Values |
|---|---|---|
color |
The foreground / text color if the current theme is a dark theme |
See Colors section |
background_color |
The background color if the current theme is a dark theme |
See Colors section |
color_2 |
The foreground / text color if the current theme is a light theme |
See Colors section |
background_color_2 |
The background color if the current theme is a light theme |
See Colors section |
extends |
Inherit from parent style |
N/A |
bold |
Make the current item bold (applies to both light and dark themes) |
true or false (defaults to false) |
italic |
Make the current item italic (applies to both light and dark themes) |
true or false (defaults to false) |
textmate_scope |
See Textmate Scopes section |
|
ace_scope |
The scope to use when exporting to Ace Editor. If nothing is specified here, and the current scope does not extend another scope, then the default scope will be inherited from the most significant Textmate scope (which defaults to 'text' if nothing is specified). |
See Textmate Scopes section |
pygments_scope |
The scope to use when exporting to Pygments. If nothing is specified here, and the current style does not extend another style, then the default scope to use will be 'String'. |
See Pygments Rouge Scopes section |
suppress_scope_conflict_warning |
If set to true, then we suppress the warning when multiple Iro internal scopes map to the same exporter scope (for any of the exporters). There may be many reasons to use multiple scopes to map to the same scope as an endpoint, therefore we provide a flag to switch off warnings when this occurs (although a lower level warning will still be available on the overview screen). |
true or false (defaults to false) |
3.3. Context
A context (or lexical state) contains an ordered list of match expressions with associated command with each command performing some operation should the regular expression match.
For example, the Java langauge has the keyword for. If defining a syntax highlighter for Java, you may wish to provide a style/color for keywords such as for. If there were only a single lexical state (AKA context), then for would be syntax highlighted as a keyword, even if in contained in double quotes.
We take for granted that a keyword in quoted text is not a keyword - but a syntax highlighter needs to understand how to transition the state from a regular code block to quoted text.
If regular expression matches then typically the match cursor will move to the end of the matched region. The match cursor is the place at which the engine is currently evaluating text.
When Iro is performing a render, a context item within a context may push a new context onto the context stack or pop the current context from the stack.
contexts [] { main : context { } }
3.4. Context Items
3.4.1. Pattern
| Please notice that regular expressions use the \= operator. This is a feature of the Rion object notation language described here |
The simplest kind of context item is the pattern matcher.
: pattern { regex \= (for|if|var|function) styles [] = .keyword; }
The pattern matcher simply matches from the current cursor position (to the end of the line), and if matched, assigns one or more styles to the matched text. The pattern matcher does not alter the context stack in any way.
Multiple capture styles may captured in a single regular expression, but never ever overlap groups or omit characters from a match. See : non-overlapping groups.
: pattern { regex \= (group)(\s*)(\{) styles [] = .keyword, .whitespace, .punctuation; }
Please see the algorithm section for how these match patterns are utlized in relation to the current line cursor.
When Iro is performing a debug render (as opposed to translating into alternative grammar formats), the match that closest to the line cursor is the match that will be selected. Upon matching, if the first match is not at offset 0 from the current line and column cursor position, non matched characters are emitted to the renderer without a style.
The matched text alongside corresponding styles will then be sent to a renderer, the line cursor will be moved forward, and the remainder of the line (or the start of the next line if zero characters remain on line) will be tested against context matchers in order in the same context again.
If the regular expression cannot be matched, then the next command is evaluated. If all regular expressions do not match then the remainder of the line is emitted with no associated style and the line cursor movest to the beginning of the next line.
3.4.2. Pop
| Please notice that regular expressions use the \= operator. This is a feature of the Rion object notation language described here |
A pop operation pops the current context off the stack. Iro maintains a stack of contexts, typically traversed through pushes and pops. It is important to make sure that pushes and pops align up carefully.
: pop { regex \= (") styles [] = .punctuation; }
A matched pop operation will consume the matched text, emit the matched style or styles, pop the current context from the stack. And start scanning in the new context (if the context changed).
3.4.3. End of line Pop
An EOL pop is a pop (remove the current context from the stack) that occurs when the end of the current line is reached. As such, there are no required attributes.
: eol_pop {}
3.4.4. Inline Push
Inline push and pop are useful for lexing langauges that are stateful. Most languages enter into different lexical states. The most commmon type of lexical state might be quoted text.
An inline push pushes its own internal inline context on a stack of contexts maintained by Iro (or any of the supported exporters).
There are two modes in which an inline push operates:
-
Default Style Provided
-
Additional match items provided
There follows two examples of an inline push, for handling text within quotes.
Basic Inline Push
| Please notice that regular expressions use the \= operator. This is a feature of the Rion object notation language described here |
A basic inline push uses a regular expression to denote when the engine to enter the inline context. Once within the context, all items that are matched before the : pop {} item will be assigned to the default style - which must be provided.
In this variation, there must always exist a : pop {} item within the inline push, and no more inline items. This will be validated when loading a .iro definition file. If you forget about it, the engine will remind you.
An inline push can span over any number of lines, but a maximum of one line of text at a time will only ever be evaluated for a match.
: inline_push { regex \= (") styles [] = .punctuation; default_style = .quoted_text; : pop { regex \= (") styles [] = .punctuation; } }
Complex Inline Push
| Please notice that regular expressions use the \= operator. This is a feature of the Rion object notation language described here |
Sometimes a basic inline push will not satisfy requirement. A common example of this is when handling escaped text. For example, you wish to place a literal double quote character within double quotes.
In these cases, the basic inline push would not be sufficient.
In this variation, the first item of the inline push must be a :pop {} item. Failure to place exactly one : pop {} item within the :inline_push {} item will invoke the wrath of the compiler.
The default style attribute is not required if there are additional items AFTER the : pop {}
In this particular example, a pattern is placed after the pop to deal with escaped double quotes. Even though the pop has the top priority for matching, the earliest match always wins, so \" would be matched before ", as the backslash would be closer to the line cursor. As this pattern would then consume both the backslash and the double quote, we now have support for syntax highlighting escape characters independently within an inner lexical state / context.
Inline pushes may be embedded too, or may be contained within independent comtexts and referenced via includes.
| See Pitfalls section for explanation on (\\(?:\\|")) regular expression. |
: inline_push { regex \= (") styles [] = .punctuation; : pop { regex \= (") styles [] = .punctuation; } : pattern { regex \= (\\(?:\\|")) styles [] = .escaped_text; } : pattern { regex \= ([^"\\]+) styles [] = .quoted_text; } }
3.4.5. Push
| Please notice that regular expressions use the \= operator. This is a feature of the Rion object notation language described here |
Push is the same type of behaviour as : inline_push except instead of entering an inline context, it enters an explicit new context.
In textmate compatibility mode (the default mode of operation), only one context may be pushed onto the stack at one time. If this compatibility mode is disabled, then it is permitted to push more than one context onto the stack upon a match occurring.
| See Pitfalls section for explanation on (\\(?:\\|")) regular expression. |
main : context { : push { regex \= (") styles [] = .punctuation; context [] = inside_quotes; } } inside_quotes : context { : pop { regex \= (") styles [] = .punctuation; } : pattern { regex \= (\\(?:\\|")) styles [] = .escaped_text; } : pattern { regex \= ([^"\\]+) styles [] = .quoted_text; } }
3.4.6. Include
The 'include' context item allows the contents of other contexts to be referenced and imported as if they were part of the current context.
That is, if we reference a context with ten context items, those ten context items will be copied and pasted into the current context.
Recursive includes loops are flagged by the compiler.
: include "comments" ;
Sample Use Of Include
contexts[] { main : context { : pattern { regex \= (if|then|something) styles[] = .keyword; } : include "comments" ; } comments : context { : pattern { regex \= (//.*) styles[] = .comment; } : inline_push { regex \= (/\*) styles [] = .comments; default_style = .comments : pop { regex \= (.*?\*/) styles [] = .comments; } } } }
3.5. Advanced Techniques
3.5.1. Constants
In Iro, any attribute that starts with two underscores is deemed to be a constant.
Constants may be referred to using the $${} syntax to reference constant value attributes. Any number of constants may be utilized as long as they start with two underscore characters.
Constants can be useful for adhering to (DRY) principles.
__id = [a-zA-Z][0-9a-zA-Z]*(?:_[0-9a-zA-Z]+)* : pattern { regex \= (\^$${__id}) styles [] = .varname; } : pattern { regex \= (\$$${__id}) styles [] = .globalvarname; } : pattern { regex \= (\%$${__id}) styles [] = .functionname; }
3.5.2. Bracket Matching
It is possible to push the same context on the stack multiple times in a row. This technique can be used to highlight unmatched brackets.
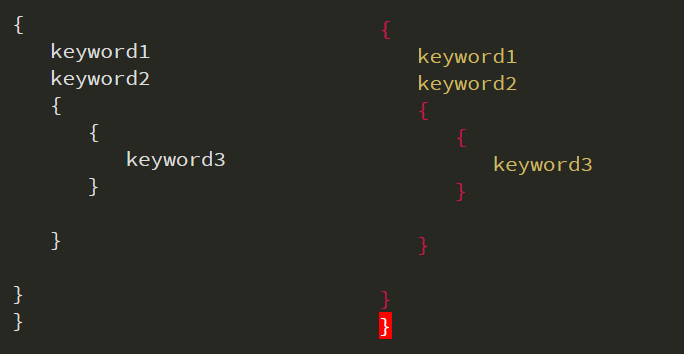
For example, consider the following grammar:
Sample code to implement bracket matching in grammar.
name = sample file_extensions [] = sample; contexts[] { main : context { : pattern { regex \= ([a-z]+) styles[] = .keyword; } : inline_push { match \= (\{) captures [] = .punctuation; : pop { match \= (\}) captures [] = .punctuation; } : include "main" ; } : pattern { regex \= (\}) styles[] = .illegal; } } } styles[] { .punctuation : style { color = red_2 } .keyword : style { color = gold } .illegal : style { color = white background_color = red } }
The result of the above grammar.
3.5.3. Perfect is the enemy of good
It is important to note that the prior JSON sample is not attempting to enforce the rules of the langauge through highlighting, beyond matched bracket highlighting (which is trivial to achieve).
By way of example, the following snippet would be syntax highlighted without error, even though it is invalid JSON:

The JSON grammar described earlier is an approximation and not intended to model the nuances of what is and is not possible in JSON. It is common practise for syntax highlighters to have undefined behaviour when faced with improper grammar.
By all means, build your model as good as you possibly can, but be aware. Perfect parsing of a language is an order of magnitude may be much more complex, for very little benefit. It is the job of the parser to highlight errors in the source, not the job of the syntax highlighter.
3.6. Pitfalls
Iro requires that every character defined in a regular expression belongs to a single group (be between ()).
Regular expressions may have one or more groups, but never zero, and no part of a match should ever belong to no group. Inner groupings are allowed but every matched character should belong to exactly one group.
3.6.1. Non-grouped match characters
: pattern { regex \= (group)\s*(\{) styles [] = .keyword, .punctuation; }
The snippet shown above shows an invalid regular expression. The '\s*' part of the regular expression does not belong to a match group (a bracketed region). This means that when emitting tokens that Iro (and other engines) would not emit characters that match this part of the expression meaning that the ungrouped characters would be lost.
The compiler will detect non matched characters.
3.6.2. Mismatch between regex capture groups and styles
: pattern { regex \= (group)(\s*)(\{) styles [] = .keyword, .punctuation; }
The snippet shown above shows that three capture groups are defined in the 'match' regular expression(correctly), but only two styles are defined.
The compiler will flag this.
3.6.3. Overlapping Matches
| Overlapping matches are a "blind-spot" in the compiler. Please take care. |
In the snippet shown below, 4 groups are defined. 3 outer groups, and one inner group. The problem here is that 'ou' is grouped twice, therefore will be emitted twice.
Although the compiler does perform a check that the number of match groups in the regular expression corresponds to the number of supplied styles, the compiler does not detect overlapping matches in regular expressions, so please be aware of the overlapping match scenario.
See Use of non-capture groups for information on how to resolve.
: pattern { regex \= (gr(ou)p)(\s*)(\{) styles [] = .keyword, .keyword,.whitespace, .punctuation; }
3.6.4. Bad Implementaton of Escape Characters
A common requirement is to use an inline push (or push) to deal with quoted text.
When dealing with literal text, there is invariable some kind of escape character handing that must occur. When dealing with escape characters, it is important to be aware of greedy regular expression that may steal the escape character.
In the below example, we enter into a literal text state upon encountering a " character. We flag that upon encountering another " character we should leave this lexcical state (aka context).
But we also wish to be able to place quotes inside the quoted block without it being a match that triggers a pop. In most languages, the backslash \ character is employed as a prefix to escape the quote so that the parser (and the syntax highlighter) knows to treat the \= pair as an escaped pair of characters.
A naive way to implement this logic is to define a rule for handling the \= pair, and define a rule that handles everything else.
: inline_push { regex \= (") styles [] = .punctuation; : pop { regex \= (") styles [] = .punctuation; } : pattern { regex \= (\\") styles [] = .escaped_text; } : pattern { regex \= ([^"]+) styles [] = .quoted_text; } }
The problem here is that the ([^"]+) expression will consume trailing backslashes. Meaning that this text "one\"" will be tokenized as follows:
| Input = "one\"" | |||
|---|---|---|---|
# |
Matched Style |
Chars Consumed |
Details |
1 |
.punctuation |
" |
Enter inline context |
2 |
.quoted_text |
one\ |
Stay in same context - FAIL HERE |
3 |
.punctuation |
" |
Pop out of context |
4 |
UNKNOWN |
" |
UNKNOWN |
Failed.
So, let’s stop the bottom pattern from picking up the backslash character:
: inline_push { regex \= (") styles [] = .punctuation; : pop { regex \= (") styles [] = .punctuation; } : pattern { regex \= (\\") styles [] = .escaped_text; } : pattern { regex \= ([^"\\]) styles [] = .quoted_text; } }
| Input = "one\"" | |||
|---|---|---|---|
# |
Matched Style |
Chars Consumed |
Details |
1 |
.punctuation |
" |
Enter inline context |
2 |
.quoted_text |
one |
Stay in same context |
3 |
.escaped_text |
\" |
Stay in same context |
4 |
.punctuation |
" |
Pop out of context (PASS) |
Passed.
Seems good, but what if we want to be able to place a literal backslash in the text too. We’d need to escape the backslash with a backslash. Let’s try "o\\ne\""
| Input = "o\\ne\"" | |||
|---|---|---|---|
# |
Matched Style |
Chars Consumed |
Details |
1 |
.punctuation |
" |
Enter inline context |
2 |
.quoted_text |
o |
Stay in same context |
3 |
.escaped_text |
\\ne\"" |
NO MATCH |
Failed.
So this time, let’s support 3 items:
-
A quote
-
A backslash followed by a backslash or a quote
-
Any text that is not a backslash or a quote
: inline_push { regex \= (") styles [] = .punctuation; : pattern { regex \= (\\(?:\\|")) styles [] = .escaped_text; } : pattern { regex \= ([^"\\]+) styles [] = .quoted_text; } }
| Input = "one\"" | |||
|---|---|---|---|
# |
Matched Style |
Chars Consumed |
Details |
1 |
.punctuation |
" |
Enter inline context |
2 |
.quoted_text |
one |
Stay in same context |
3 |
.escaped_text |
\" |
Stay in same context |
4 |
.punctuation |
" |
Pop out of context (PASS) |
Passed.
| Input = "o\\ne\"" | |||
|---|---|---|---|
# |
Matched Style |
Chars Consumed |
Details |
1 |
.punctuation |
" |
Enter inline context |
2 |
.quoted_text |
o |
Stay in same context |
3 |
.escaped_text |
\\ |
Stay in same context |
4 |
.quoted_text |
ne |
Stay in same context |
5 |
.escaped_text |
\" |
Stay in same context |
6 |
.punctuation |
" |
Pop out of context (PASS) |
Passed.
4. Scope Coverage Report
The scope coverage report is used to validate if all defined styles have been mapped to an exporter scope name, and that each has been mapped to a unique scope name.
Failure to map styles correctly to external scope names will not result in the export failing, but rather, it will issue an advisory at the time of definition file creation.
A file - "iro_scope_coverage_report.html" will be produced alongside all of the exporter textfiles.
4.1. Success Report
The following scope report corresponds to the JSON Sample shown earlier.

| Look for "No Problems Detected" |
4.2. Failure Reports
4.2.1. Style Without A Scope
The following scope report corresponds to the JSON Sample shown earlier except we deleted the textmate scope from the '.escape_char' style.
Here is the modified style:
.escape_char : style { #textmate_scope = constant.character.escape pygments_scope = String.Escape color = #0a0 background_color = #232 }
Here is the resultant report:
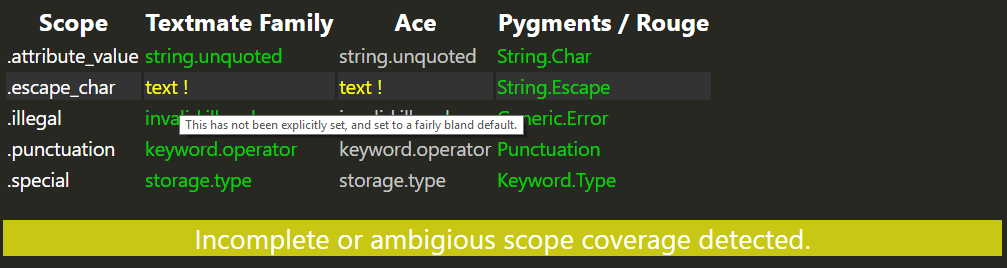
4.2.2. Multiple Styles Without A Scope
The following scope report corresponds to the JSON Sample shown earlier except we deleted the textmate scope from the '.escape_char' and 'punctuation' styles.
Here are the modified styles:
.escape_char : style { #textmate_scope = constant.character.escape pygments_scope = String.Escape color = #0a0 background_color = #232 } .punctuation : style { #textmate_scope = keyword.operator pygments_scope = Punctuation color = red_2 }
Here is the resultant report:

4.2.3. Two styles with the same scope
The following scope report corresponds to the JSON Sample shown earlier except we modified 'punctuation' style to have the same textmate scope as the '.escape_char' style.
Here are the modified styles:
.punctuation : style { textmate_scope = constant.character.escape pygments_scope = Punctuation color = red_2 }
Here is the resultant report:

5. Tutorial
These tutorials require good (but not expert) knowledge of regular expressions. If you are not familar with regular expressions and you work in development, then it would be the single best use of your time to learn them.
Consider the following code snippet of a langauge we wish to syntax highlight (you may recognise this snippet from the introduction section).
say "hello"; // This is a comment
5.1. Phase One - Define Lexing Rules
5.1.1. Analysis
First we should identify the initial state and the items we would like to syntax highlight in in the initial state.
In this first example, there is only one state (possibly two if we view quoted text as its own state).
Here are the things we wish to syntax highlight in the initial state. This does not necessarily need to be a complete list. This process is iterative.
So, let’s start with:
-
Keywords (such as 'say')
-
';' semi colon
-
Comments
5.1.2. Boilerplate
We start with a small amount of boilerplate, which can be copied and pasted from this section of the document.
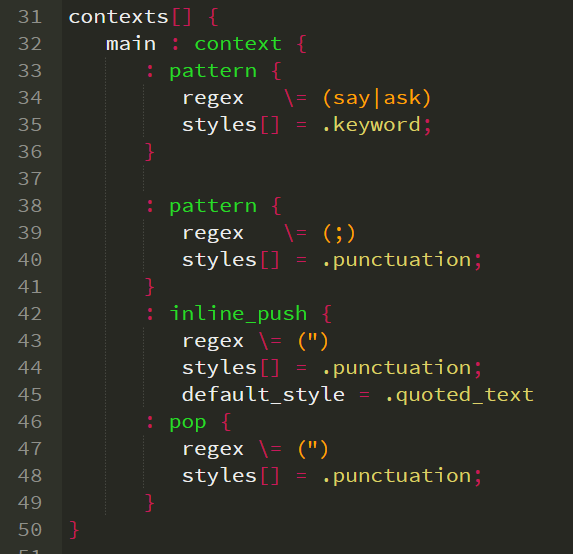
######################################## ## Header ######################################## name = tutorial1 file_extensions [] = tutorial1; ######################################## ## Styles ######################################## styles[] { } ######################################## ## Contexts ######################################## contexts[] { main : context { } }
5.1.3. Define Styles
From the 3 categories, plan to create 3 styles. Remember, style names start with period/dot (.) character by convention. This was a questionable design decision by yours truly, and it keeps me awake at night.
######################################## ## Styles ######################################## styles[] { .keyword : style { color = yellow } .punctuation : style { color = orange } .quoted_text : style { color = cyan } .comment : style { color = grey } }
Iro currently only supports the dark theme for debugging rendering (render against a dark backdrop).
5.1.4. Define Simple Regular Expression Patterns
######################################## ## Contexts ######################################## contexts[] { main : context { : pattern { regex \= (say|ask) styles[] = .keyword; } : pattern { regex \= (;) styles[] = .punctuation; } } }

5.1.5. Using Inline Push For Quoted Text
Now we create an inline push rule to handle quoted text. We enter an inline lexical state upon encountering the " character. We only pop out of the state when we encounter another " character. All text handled before the closing " character is assigned the default style of ".quoted_text".
: inline_push { regex \= (") styles[] = .punctuation; default_style = .quoted_text : pop { regex \= (") styles[] = .punctuation; } }

5.1.6. Handling single line comments
This is a fairly simple rule. It looks for // and then consumes everthing after this. Remember, we are using a line based matcher, so .* only takes us to the end of the line.
: pattern { regex \= (//.*) styles[] = .comment; }

5.1.7. Debugging
The debug render of the document contains a lot of useful debugging information. Every single piece of text and whitespace has a hiver which displays the current style and stack for the current location.
In this below diagram, it displays which rules have been executed in which order, using line numbers; very useful in larger models.
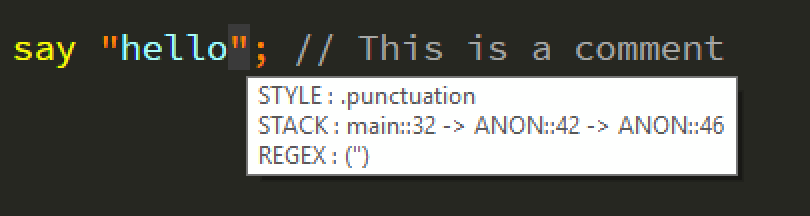
Reading the stack
In the above image, hovering over the double quote on the right shows the matched style for the matched region (the " following hello). The matched style in this example is ".punctuation".
As most context items in Iro are anonymous, then the stack trace uses the ANON alias to represent unidentified context items.
The stack reads "main::32 → ANON::42 → ANON::46"
All stack traces will start inside the main context. The number after main represents the line number in the corresponding .iro file where to find the current context or context item.
Breaking the stack trace down further:
-
main::32 → Whilst in the main context
-
ANON::42 → We match the regular expression (\") which puts us into the inline_push context.
-
ANON::46 → Whilst in the context of inline push (line 42) we encounter a matching regular expression (\") for popping back into the main context.
For the ';' character following the shown screenshot we can imply would have a stack trace as follows:
-
main::32 → Whilst in the main context
-
ANON::38 → Match the (;) regular expression, without changing context.
5.1.8. Assigning ids to context items (UIDs)
In order to make stack traces easier to read, match items are able to assign unique identifiers to context items. Contexts already have ids.
UIDs must be unique across all declared UIDs in the .iro file and must start with 'uid_'. This is to make it clear when a stack trace element is a context, or when it is a context (as contexts are not permitted to start with the 'uid_' prefix).
: pattern { uid = uid_single_line_comment regex \= (//.*) styles[] = .comment; }
5.2. Phase Two - Assign Scopes & Export
Phase 2 involves the assignment of various exporter scopes to styles so that when derived grammars are generated, there is enough entropy to be able to syntax highlight.
The first thing we do is to review the scope coverage report:
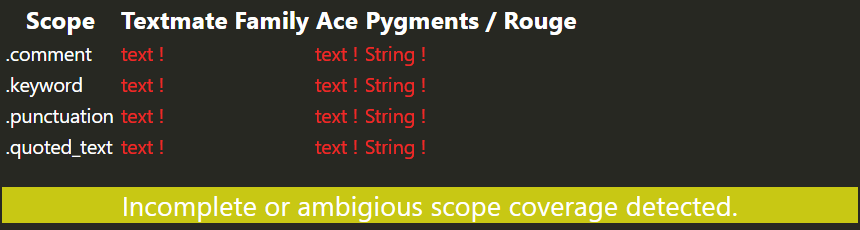
5.2.1. Add in some scopes to existing styles
Adding in a textmate scope and a pygments scope is required to obtain the greenlight (at present). Ace inherits from textmate, Rouge inherits from Pygments.
.keyword : style { color = yellow textmate_scope = keyword pygments_scope = Keyword } .punctuation : style { color = orange textmate_scope = punctuation pygments_scope = Punctuation }
And here is the report:

5.2.2. Obtain the greenlight
We assign textmate and pyments scopes to the final two styles. Now we have full scope coverage across all supported exporters.
.quoted_text : style { color = cyan textmate_scope = string pygments_scope = String } .comment : style { color = grey textmate_scope = comment pygments_scope = Comment }
And here is the report:

5.2.3. Generate Exporters
If running from the command line, the created syntax highlighting definition files are available in the 'iro-gen' folder (they are generated at the same time as debug builds).
If running from the web UI, select the exporter specific tab to see the appropriate exporters. The download button may be used to download all generated exporters in a zipfile.
It is not in the scope of this document to describe how to import these files into various editors/IDEs/Frameworks.
6. Syntax Highlighting Algorithm
6.1. Line-Based Matching
The syntax highlighting algorithm is quite common across technologies. Iro uses line based matching,. A regular expression is not permitted to match across multiple lines. The start of a line matches
Pygments and Rouge typically offer full document based matching, which is more flexible. Compatibility between line based matching grammars and document based matching grammars is handled with logic in the exporters. All regular expressions should be written to assume line-based matching.
6.2. Walkthrough
In this visualization of the algorithm, the cursor will be represented by the '^' char. It should not be considered part of the document being evaluated. Please do not confuse it with the start of line character in a regular expression.
Consider a sample document containing the following text:
^my document ; my document ; x my documen
Imagine that we have just one context defined. And the context has the following three regular expressions
-
(my)
-
(document)
-
(;)
The above listed regular expressions are defined via the 'pattern' command within a context in the Iro file format. For the purposes of detailing the scanning algorithm, we only need to show the regular expressions themselves.
For the current context, from the current cursor position to the end of the line, evaluate a list of regular expressions, and if matched, do something, and move the cursor to the end of the match.
We attempt to match the first entire line 'my document ; my document ;' using the first regular expression (my), and good news, it matches. A full match is not required for the whole line, the match just needs to be able to match somewhere on the line.
| If the match does not start exactly from the cursor position, then other regular expressions will be evaluated and the regular expression that matches closes to the cursor is nominated winner. The longest match does not win (consume the matched characters), the match that starts closest to the cursor wins (consumes the matched characters). |
my^ document ; my document ; x my documen
The cursor has moved to the end of 'my' in the document. Notice that the whitespace has not been consumed after 'my'. The operation that is performed on the consumed text is irrelevant to the algorithm, but will be described later on. Assume that regular expression matches are simply consuming text then moving a virtual cursor.
Now the remainder of the current line contains ' document ; my document ; x' (without quotes). We now test against the first regular expression '(my)'. It matches ! But the position of the match is at an offset of 12 from the remainder of the line being evaluated. If the offset is greater than 0 for the match, then the matching continues.
Now we compare the regular expression (document) against ' document ; my document ; x'. It matches. This time the offset is just 1. Still not zero. So we perform another regular expression test. This time we test for (;). It matches - but at offset 10.
So now we have 3 matches, but the match with the closest offset will be chosen. That is the 2nd regular expression (document). The length of the match is 8, and the offset of the match is 1. So the first character is flagged as unmatched, and the cursor is moved along 9 characters.
my document^ ; my document ; x my documen
Now we are evaulating the string ' ; my document ; x'. None of the 3 matches start from offset 0, but the (;) regular expression is at offset 1. So we skip the space again, and consume the ';' matched character. The cursor moves along 2 characters.
my document ;^ my document ; x my documen
Now we are evaulating the string ' my document ; x'. None of the 3 matches start from offset 0, but the (my) regular expression is at offset 1. So we skip the space again, and consume the 'my' matched characters. The cursor moves along 3 characters.
my document ; my^ document ; x my documen
Now we are evaulating the string ' document ; x'. None of the 2 matches start from offset 0, but the (document) regular expression is at offset 1. So we skip the space again, and consume the 'document' matched characters. The cursor moves along 9 characters.
my document ; my document^ ; x my documen
Now we are evaulating the string ' ; x'. There is just one match. The (;) regular expression is at offset 1. So we skip the space again, and consume the ';' matched character. The cursor moves along 2 characters.
my document ; my document ;^ x my documen
Now we are evaulating the string ' x'. Nothing matches at all. The remainder of the line is skipped, and the cursor moves down to the next line.
my document ; my document ; x ^my documen
Now we are evaulating the string 'my documen' (on the second line). The first regular expression (my) matches, at offset 0, so no more expressions are needed to be evaluated. The cursor moves forward two characters.
my document ; my document ; x my^ documen
Now we evaluate the string ' documen'. None of the three regular expressions match, so the remaining characters are skipped to the end of the line.
my document ; my document ; x my documen^
We have reached the end of the document.
6.2.1. Skipped characters
When the scanner skips characters (like the ' x' and ' ' and ' documen') in the walkthrough. These characters are emitted with no style associated with them.
All matches emit events, and these events are handled by the highlighter.
Iro renders text for the purposes of debugging, but its algorithm simulates the textmate and Ace editor algorithm (derived from observation).
7. Appendices
7.1. Java API
The Java API is subject to change. It will only render using the default style defined in the .iro file.
For full stack trace debugging, call .setDebug(true).setConcise(false) on the HtmlRenderer object.
import xyz.iroiro.iro.Iro;
import xyz.iroiro.iro.engine.HtmlRenderer;
import xyz.iroiro.iro.engine.IroTokenizer;
import xyz.iroiro.iro.engine.LanguageModel;
import xyz.iroiro.iro.engine.Renderer;
public class YourClass {
public static void render(final String text) throws InvalidModelException, IOException {
final java.io.File iroDefinitionFile = ... ;
HtmlRenderer renderer = new HtmlRenderer().setDebug(true).setConcise(true);
new IroTokenizer(){
@Override
public String getText() { return text; }
@Override
public LanguageModel getLanguageModel() { return Iro.loadLanguageModel(locationOfIroFile); }
@Override
public Renderer getRenderer() { return renderer; }
}.execute();
// Will contain escaped html <pre> block, does not require any css to render.
return renderer.toString();
}
}7.2. Lookup Tables
Iro supports varios tokens in the styles section. Acceptable values for those tokens are described in this section.
7.2.1. Textmate/Atom/Ace Scopes
Here are a list of common Textmate scopes. This list is advisory. Other scopes may be supplied. The Textmate website contains some additional information on how to assign these scopes.
Ace editor generally mirrors the scopes used by Textmate in order to be semi-compatible using an adapted version of the Textmate lexing algorithm.
If assigning a Textmate scope to a style, then the Ace scope inherits the same scope. If an Ace scope is explicitly set, then this overrides the inheritance.
-
comment
-
comment punctuation
-
comment.block.documentation
-
comment.block.preprocessor
-
comment.documentation
-
constant
-
constant.character
-
constant.character punctuation
-
constant.character.entity
-
constant.character.escape
-
constant.language
-
constant.language punctuation
-
constant.numeric
-
constant.numeric punctuation
-
constant.numeric.line-number.find-in-files
-
constant.other
-
constant.other punctuation
-
constant.other.color
-
constant.other.symbol
-
entity
-
entity.name
-
entity.name.class
-
entity.name.class punctuation
-
entity.name.exception
-
entity.name.filename
-
entity.name.filename.find-in-files
-
entity.name.function
-
entity.name.function punctuation
-
entity.name.section
-
entity.name.tag
-
entity.name.tag punctuation
-
entity.name.tag.css
-
entity.name.type
-
entity.name.type.class
-
entity.other
-
entity.other.attribute-name
-
entity.other.attribute-name punctuation
-
entity.other.attribute-name.id
-
entity.other.inherited-class
-
entity.other.inherited-class punctuation
-
invalid
-
invalid.deprecated
-
invalid.illegal
-
keyword
-
keyword punctuation
-
keyword.control
-
keyword.operator
-
keyword.other.special-method
-
keyword.other.unit
-
markup
-
markup.bold
-
markup.changed
-
markup.deleted
-
markup.deleted punctuation
-
markup.error
-
markup.heading
-
markup.heading punctuation.definition.heading
-
markup.inserted
-
markup.inserted punctuation
-
markup.italic
-
markup.list
-
markup.output
-
markup.prompt
-
markup.quote
-
markup.raw
-
markup.raw.inline
-
markup.traceback
-
markup.underline
-
message.error
-
meta
-
meta.class
-
meta.diff
-
meta.diff punctuation
-
meta.diff.header
-
meta.diff.header punctuation
-
meta.diff.header.from-file
-
meta.diff.header.to-file
-
meta.diff.index
-
meta.diff.range
-
meta.function-call
-
meta.link
-
meta.link punctuation
-
meta.property-name
-
meta.property-value constant
-
meta.property-value constant.numeric
-
meta.property-value keyword
-
meta.require
-
meta.selector
-
meta.selector entity
-
meta.selector entity punctuation
-
meta.separator
-
meta.structure.dictionary.json string.quoted.double.json
-
meta.tag string punctuation
-
meta.tag string.quoted
-
meta.tag string.quoted constant.character.entity
-
meta.tag.sgml.doctype
-
none
-
punctuation
-
punctuation.definition
-
punctuation.definition.array
-
punctuation.definition.bold
-
punctuation.definition.comment
-
punctuation.definition.entity
-
punctuation.definition.italic
-
punctuation.definition.parameters
-
punctuation.definition.string
-
punctuation.definition.tag
-
punctuation.definition.variable
-
punctuation.section.embedded
-
storage
-
storage punctuation
-
storage.type
-
storage.type punctuation
-
string
-
string punctuation
-
string source
-
string.other.link
-
string.regexp
-
support
-
support.class
-
support.class punctuation
-
support.constant
-
support.constant punctuation
-
support.function
-
support.function punctuation
-
support.other.variable
-
support.type
-
support.type punctuation
-
support.type.property-name
-
support.variable
-
text
-
text source
-
text.html.markdown punctuation
-
variable
-
variable punctuation
-
variable.interpolation
-
variable.language
-
variable.other
-
variable.other punctuation
-
variable.parameter
-
variable.parameter.function
7.2.2. Pygments / Rouge
Here are the pygments/rouge scopes that are supported by Iro. This list is advisory. Other scopes may be supplied
-
Rouge / Pygments Scopes
-
Comment
-
Comment.Multiline
-
Comment.Preproc
-
Comment.Single
-
Comment.Special
-
Generic
-
Generic.Deleted
-
Generic.Emph
-
Generic.Error
-
Generic.Heading
-
Generic.Inserted
-
Generic.Output
-
Generic.Prompt
-
Generic.Strong
-
Generic.Subheading
-
Generic.Traceback
-
Keyword
-
Keyword.Constant
-
Keyword.Declaration
-
Keyword.Namespace
-
Keyword.Pseudo
-
Keyword.Reserved
-
Keyword.Type
-
Literal
-
Literal.Date
-
Name
-
Name.Attribute
-
Name.Builtin
-
Name.Builtin.Pseudo
-
Name.Class
-
Name.Constant
-
Name.Decorator
-
Name.Entity
-
Name.Exception
-
Name.Function
-
Name.Label
-
Name.Namespace
-
Name.Other
-
Name.Tag
-
Name.Variable
-
Name.Variable.Class
-
Name.Variable.Global
-
Name.Variable.Instance
-
Number
-
Number.Bin
-
Number.Float
-
Number.Hex
-
Number.Integer
-
Number.Integer.Long
-
Number.Oct
-
Operator
-
Operator.Word
-
Punctuation
-
String
-
String.Backtick
-
String.Char
-
String.Doc
-
String.Double
-
String.Escape
-
String.Heredoc
-
String.Interpol
-
String.Other
-
String.Regex
-
String.Single
-
String.Symbol
7.2.3. Colors
Colors within styles can use either a hex value (in the #000-#fff format) or a color alias, as described in the following table.
Do not worry about "hardcoding" colors into your definition file. These colors are only to be used for debugging purposes as when emitting grammar definitions for external syntax highlighters, colors defined within a style will be completely ignored.
| Alias | 12-bit Color Alias |
|---|---|
black |
#000 |
white |
#fff |
blue |
#00f |
brown |
#a52 |
cyan |
#aff" |
gold |
#cb6 |
green |
#0f0 |
grey |
#aaa |
light_blue |
#19f |
light_green |
#9c2 |
light_grey |
#ddd |
light_yellow |
#ffc |
navy |
#008 |
orange |
#f80 |
pink |
#f0c |
purple |
#a2f |
violet |
#e8e |
violet_red |
#d29 |
red |
#f00 |
red_2 |
#c15 |
yellow |
#ff0 |
7.3. Rion Object Notation
Iro’s configuration is hosted upon the 'Rion' object notation.
Rion supports the concept of objects, collections and objects. Only the feature relevant to Iro will be detailed in this section.
7.3.1. Objects
A blank document will be parsed into containing a single root object with no contents. Every valid item parsed within a document is added to the root document. Within the root object and within any object, an object can contain attributes, objects and collections. All items within an object must be identified.
In Rion, all objects must have a type but id is optional.
.comments : style { // Some contents }
| In the above example, the '.' at the beginning of the beginning of scope is not required by the object notation language, but is a convention when describing Iro scopes. |
In this snippet, we are defining an unidentified object of type 'pattern'. Objects without type are usually order sensitive (order is maintained).
: pattern { }
7.3.2. Attributes
Basic attributes are simple keys and values.
textmate_uuid = c03f1283-7bde-4b48-bfa5-7bc40ef922ab
| Leading and trailing whitespace characters are ignored. |
Rion supports a native Regular Expression syntax such that no escaping is performed.
match \= (\s*\:\s*)(foo)
Some attributes may involve multiple values.
styles [] = .punctuation, .quoted_text, .punctuation;
7.3.3. Collections
Collections are containers for objects. If the order of objects in a sequence is important then that is a reason to use a collection.
contexts [] { : pattern { regex \= (say) styles [] = .keyword; } }
In the above example, the collection is 'contexts [] { … }' and it contains a single typed and unidentified object (of type patten).
7.4. FAQ
Lookbehind regular expressions are not permitted as the lowest common denominator regular expression implementations do not support them (JavaScript).
If there is interest I may add a flag to force lookbehinds to be accepted even though it is likely to break compatibility with Ace and Atom (which both use JavaScript regular expression engines).
Not yet. This may follow in later releases.
I hope so.
No.
Semantic highlighting involves a deep knowledge of the structure of a language in order to colour language elements differently depending on one of a variety of factors. An example of this is highlighting global variables differently to local variables.
Such highlighting is not supported by Iro, nor is it supported by any of the exporters on offer - the the best of my knowledge.
7.5. Recommended Reading
-
A case against syntax highlighting by Linus Åkesson
-
Syntax Highlighting Off by Robert Melton
7.6. Recommended Tools
In my opinion DebugEx really is the best visualization tool for creating and debugging individual regular expressions.
7.7. Limitation of Liabilities
Iro is copyright of Consoli Limited, 2017, all rights reserved.
Consoli Limited is not responsible for, and expressly disclaims all liability for, damages of any kind arising out of use, reference to, or reliance on any information contained or generated from the Iro application and from information contained within this document.
The information in this document and the Iro application itself are provided "as is" without warranty of any kind, either expressed or implied, including, but not limited to, the implied warranties of merchantability and fitness for a particular purpose
7.8. Contact
Twitter: @ainslec
Email: [email protected]
8. Sample Exporter Output
This section contains derived grammars, corresponding to the Tutorial section that are useful for reference purposes but do not flow in the context of a document.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple Computer//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>fileTypes</key>
<array>
<string>tutorial1</string>
</array>
<key>name</key>
<string>tutorial1</string>
<key>patterns</key>
<array>
<dict>
<key>include</key>
<string>#main</string>
</dict>
</array>
<key>scopeName</key>
<string>source.tutorial1</string>
<key>uuid</key>
<string></string>
<key>repository</key>
<dict>
<key>main</key>
<dict>
<key>patterns</key>
<array>
<dict>
<key>match</key>
<string>(say|ask)</string>
<key>captures</key>
<dict>
<key>1</key>
<dict>
<key>name</key>
<string>keyword.tutorial1</string>
</dict>
</dict>
</dict>
<dict>
<key>match</key>
<string>(;)</string>
<key>captures</key>
<dict>
<key>1</key>
<dict>
<key>name</key>
<string>punctuation.tutorial1</string>
</dict>
</dict>
</dict>
<dict>
<key>begin</key>
<string>(\")</string>
<key>beginCaptures</key>
<dict>
<key>1</key>
<dict>
<key>name</key>
<string>punctuation.tutorial1</string>
</dict>
</dict>
<key>contentName</key>
<string>string.tutorial1</string>
<key>end</key>
<string>(\")</string>
<key>endCaptures</key>
<dict>
<key>1</key>
<dict>
<key>name</key>
<string>punctuation.tutorial1</string>
</dict>
</dict>
</dict>
<dict>
<key>match</key>
<string>(//.*)</string>
<key>captures</key>
<dict>
<key>1</key>
<dict>
<key>name</key>
<string>comment.tutorial1</string>
</dict>
</dict>
</dict>
</array>
</dict>
<key>main__1</key>
<dict>
<key>patterns</key>
<array>
</array>
</dict>
</dict>
</dict>
</plist>Ace Editor supports a feature whereby you can try out the grammar online with a variety of stylesheets. See the URL contained in the generated exporter.
/*
* To try in Ace editor, copy and paste into the mode creator
* here : http://ace.c9.io/tool/mode_creator.html
*/
define(function(require, exports, module) {
"use strict";
var oop = require("../lib/oop");
var TextHighlightRules = require("./text_highlight_rules").TextHighlightRules;
/* --------------------- START ----------------------------- */
var Tutorial1HighlightRules = function() {
this.$rules = {
"start" : [
{
"token" : ["keyword"],
"regex" : "(say|ask)"
},
{
"token" : ["punctuation"],
"regex" : "(;)"
},
{
"token" : ["punctuation"],
"regex" : "(\\\")",
"push" : "main__1"
},
{
"token" : ["comment"],
"regex" : "(//.*)"
},
{
defaultToken : "text",
}
],
"main__1" : [
{
"token" : ["punctuation"],
"regex" : "(\\\")",
"next" : "pop"
},
{
defaultToken : "string",
}
]
};
this.normalizeRules();
};
/* ------------------------ END ------------------------------ */
oop.inherits(Tutorial1HighlightRules, TextHighlightRules);
exports.Tutorial1HighlightRules = Tutorial1HighlightRules;
});'fileTypes' : [
'tutorial1'
]
'name' : 'tutorial1'
'patterns' : [
{
'include' : '#main'
}
]
'scopeName' : 'source.tutorial1'
'uuid' : ''
'repository' : {
'main' : {
'patterns' : [
{
'match' : '(say|ask)'
'captures' : {
'1' : {
'name' : 'keyword.tutorial1'
}
}
}
{
'match' : '(;)'
'captures' : {
'1' : {
'name' : 'punctuation.tutorial1'
}
}
}
{
'begin' : '(\\")'
'beginCaptures' : {
'1' : {
'name' : 'punctuation.tutorial1'
}
}
'contentName' : 'string.tutorial1'
'end' : '(\\")'
'endCaptures' : {
'1' : {
'name' : 'punctuation.tutorial1'
}
}
}
{
'match' : '(//.*)'
'captures' : {
'1' : {
'name' : 'comment.tutorial1'
}
}
}
]
}
'main__1' : {
'patterns' : [
]
}
}%YAML 1.2
---
name: tutorial1
scope: source.tutorial1
file_extensions: [ tutorial1 ]
contexts:
main:
- match: (say|ask)
captures:
0: keyword.tutorial1
- match: (;)
captures:
0: punctuation.tutorial1
- match: (\\\")
captures:
0: punctuation.tutorial1
push:
- match: (\\\")
pop: true
captures:
0: punctuation.tutorial1
- match: (.)
captures:
0: string.tutorial1
- match: (//.*)
captures:
0: comment.tutorial1
- match: (.)
captures:
0: text.tutorial1from pygments.lexer import RegexLexer, bygroups
from pygments.token import *
import re
__all__=['Tutorial1Lexer']
class Tutorial1Lexer(RegexLexer):
name = 'Tutorial1'
aliases = ['tutorial1']
filenames = ['*.tutorial1']
flags = re.MULTILINE | re.UNICODE
tokens = {
'root' : [
(u'(say|ask)', bygroups(Keyword)),
(u'(;)', bygroups(Punctuation)),
(u'(\\\")', bygroups(Punctuation), 'main__1'),
(u'(//.*)', bygroups(Comment)),
('(\n|\r|\r\n)', String),
('.', String),
],
'main__1' : [
(u'(\\\")', bygroups(Punctuation), '#pop'),
('(\n|\r|\r\n)', String),
('.', String),
]
}# -*- coding: utf-8 -*- #
module Rouge
module Lexers
class Tutorial1 < RegexLexer
title "tutorial1"
tag 'Tutorial1'
mimetypes 'text/x-tutorial1'
filenames '*.tutorial1'
state:root do
rule /(say|ask)/, Keyword
rule /(;)/, Punctuation
rule /(\")/, Punctuation, :main__1
rule /(\/\/.*)/, Comment
rule /(\n|\r|\r\n)/, String
rule /./, String
end
state:main__1 do
rule /(\")/, Punctuation, :pop!
rule /(\n|\r|\r\n)/, String
rule /./, String
end
end
end
end